Now Reading: Batch vs Streaming Data Processing: What’s the Difference?
-
01
Batch vs Streaming Data Processing: What’s the Difference?


Core Concepts of Batch and Streaming Data Processing
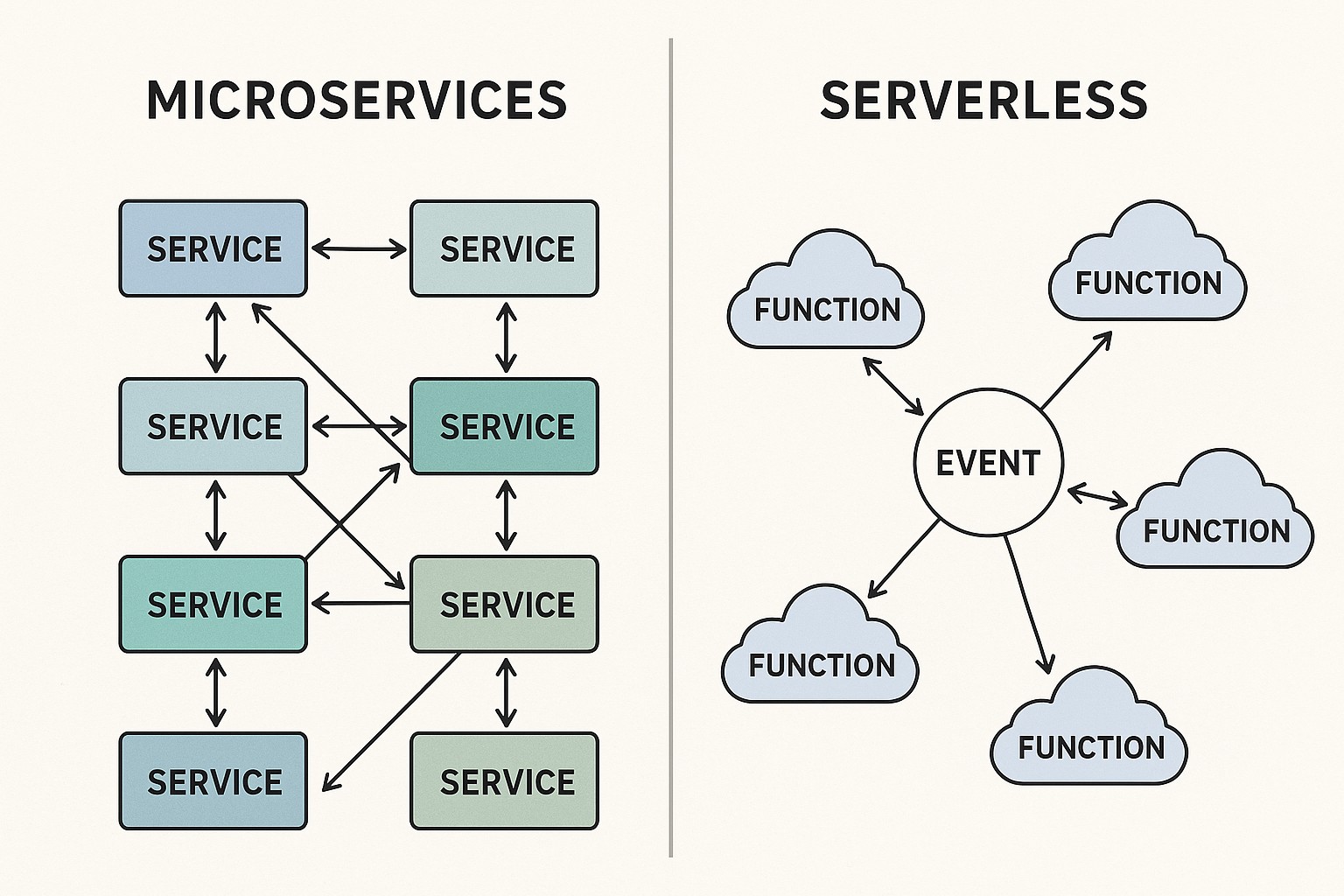
In modern data architectures, batch and streaming data processing represent two fundamental paradigms for turning raw information into actionable insight. Batch processing operates on large volumes of data collected over a period of time, then runs a predefined set of transformations to produce a complete result set. This pattern is well suited to activities such as historical reporting, data consolidation from multiple source systems, and periodic compliance or reconciliations common in health information management. It emphasizes throughput, reproducibility, and deterministic results, often benefiting from strong data quality controls and auditing capabilities that align with regulatory requirements.
Streaming processing, by contrast, treats data as an ongoing sequence of events that are processed as they arrive or within short time windows. This approach enables near real-time analytics, live monitoring, and timely alerting, which are increasingly important for patient safety, fraud detection, and operational optimization in healthcare environments. Streaming systems must handle event ordering, late data, and stateful computations across time windows, all while preserving fault tolerance and low latency. The two paradigms are not mutually exclusive; many organizations design hybrid pipelines that leverage batch for historical analysis and streaming for timely decision support within the same overall data platform.
– Batch
– Data velocity: High-volume data accumulated over a cycle, such as daily claims feeds, patient demographics reconciliation runs, or research-grade datasets pulled from multiple systems.
– Typical latency: Minutes to hours, depending on data source freshness, transformation complexity, and scheduling constraints.
– Typical technologies: Hadoop MapReduce (historical baseline), Apache Hive for SQL-on-Hadoop, Spark Batch for iterative transformations, and traditional data warehouse or data lake ETL tooling.
– Streaming
– Data velocity: Continuous streams from clinical systems, IoT devices, payment gateways, and event logs.
– Typical latency: Seconds to milliseconds, with variations based on network, serialization, and processing guarantees.
– Typical technologies: Apache Kafka for durable event transport, Apache Flink for stateful stream processing, Spark Streaming or Structured Streaming for micro-batch or continuous processing, and cloud-native event hubs or message queues.
Batch Processing: Use Cases and Technologies
In the context of healthcare data integration, batch processing plays a pivotal role in bringing disparate data sources into a coherent, analyzable form. Periodic ETL jobs gather information from electronic health records, billing systems, laboratory results, and claims repositories, cleanse inconsistencies, reconcile patient identifiers, and load the results into a centralized data store or a data warehouse designed for reporting and risk analytics. This approach is particularly effective for regulatory reporting, long-horizon trend analysis, and retrospective research that requires stable, auditable datasets. With batch, teams can optimize for throughput and cost efficiency, running heavy computations during off-peak hours to minimize contention on source systems and to align with governance cycles.
A well-designed batch pipeline in healthcare emphasizes data lineage, versioning, and reproducibility. Operators can rerun historical transformations, verify audit trails, and validate results against predefined metrics before distributing them to downstream consumers. Organizations often implement schema validation, data quality dashboards, and lineage metadata as part of batch workflows to satisfy compliance mandates and to support data stewardship programs. While batch may introduce latency relative to real-time needs, it remains indispensable for consolidating patient history, aggregating population health indicators, and feeding enterprise analytics platforms with stable, reliable data foundations.
The technology choices for batch processing tend to favor mature, scalable processing frameworks and storage architectures. Many teams leverage distributed storage like data lakes or data warehouses to hold raw and curated data, then apply batch-oriented engines to execute transforms such as normalization, deduplication, conformance mapping, and slowly changing dimension handling. In healthcare, batch routines often supplement streaming components by performing long-running reconciliation, anomaly detection over accumulated data, and end-of-day or week-end aggregations that feed dashboards, billing reconciliation, and policy analytics. The result is a dependable backbone for governance, auditing, and strategic decision-making.
Streaming Processing: Real-Time Insights and Platforms
Streaming processing shifts the emphasis from periodic completeness to continuous visibility. In healthcare environments, streaming enables near real-time patient monitoring, instant anomaly detection in clinical or operational data, and timely alerting for critical events such as abnormal lab results, unusual medication interactions, or access violations. Event-driven architectures empower organizations to react quickly to changing conditions, support dynamic capacity planning, and improve patient safety through proactive interventions. However, streaming systems must contend with data quality challenges, late-arriving events, and the need to maintain consistent state across long-running queries, all while meeting stringent uptime requirements and regulatory obligations.
The platforms that power streaming workloads are designed for low latency, fault tolerance, and scalable state management. By streaming data through distributed queues and processing engines, organizations can ingest, filter, aggregate, and enrich events with minimal delays. In healthcare data integration, streaming enables real-time dashboards for operations centers, clinical decision support previews, and immediate auditing of access and changes to sensitive records. While the engineering trade-offs can be complex, the benefits include improved timeliness of insights, better operational responsiveness, and the ability to surface early indicators that were previously detectable only after retrospective analysis.
Healthcare Data Integration: Practical Considerations
When designing data pipelines for healthcare, practitioners must balance a spectrum of technical and regulatory considerations. Data provenance, privacy, and consent are central concerns; therefore, both batch and streaming solutions should incorporate robust access controls, encryption at rest and in transit, and comprehensive auditing to satisfy standards such as HIPAA and applicable regional regulations. Data quality and governance are equally critical, since inconsistent patient identifiers, conflicting test results, or misaligned terminology can undermine analytics and patient safety initiatives. A pragmatic approach often combines batch for depth and history with streaming for immediacy, ensuring that governance policies extend across both domains.
Data velocity and latency requirements should drive architecture decisions. Slow-moving enterprise analytics and historical trend analysis can be efficiently served by batch pipelines, while real-time monitoring and alerting demand streaming capabilities. In practice, healthcare teams often adopt a tiered model: batch processes produce the consolidated, cleansed data stores used for routine reporting, while streaming components populate real-time views and alerting engines that react to events as they happen. This hybrid posture maximizes reliability and timeliness without sacrificing data quality or regulatory compliance. Infrastructure costs, data retention policies, and operational maturity should also factor into the design, as streaming often entails higher complexity and ongoing operational risk.
Beyond technical concerns, organizational alignment matters. Data owners, clinical leads, and IT operations must agree on data schemas, permissible transformations, and the cadence of data refreshes. Clear service level expectations for both batch and streaming workloads help ensure that dashboards, alerts, and reporting outputs meet user needs. In healthcare, interoperability standards, semantic alignment across systems, and effective change management approaches are essential to sustaining a robust, compliant data integration program over time.
Architecture Patterns: Hybrid Approaches
Hybrid architectures combine the strengths of batch and streaming to deliver timely insights while preserving the reliability and auditability of historical data. A common pattern is to publish real-time events to a streaming platform for immediate processing, while concurrently maintaining a batch-reconciled data store for deep-dive analyses and regulatory reporting. This approach supports both operational analytics and strategic intelligence, enabling teams to monitor current conditions while preserving a stable, versioned source of truth for long-term analyses.
Here is a simplified example of a hybrid pipeline configuration that illustrates how batch and streaming components can coexist in a healthcare data integration environment. It shows daily batch processing feeding a central data warehouse, alongside a streaming path that streams events into a real-time analytics store and alerting system.
{
"pipeline": {
"batch": {
"schedule": "daily",
"sources": ["EHR_RAW", "CLAIMS_RAW", "LAB_RESULTS_RAW"],
"transforms": ["cleanse", "standardize", "deduplicate", "conform"],
"sink": "ENTERPRISE_DATA_WAREHOUSE"
},
"streaming": {
"source": "KAFKA_EDW_EVENTS",
"transforms": ["enrich_with_patient_master", "validate_event"],
"windows": "5m",
"alerts": {
"enabled": true,
"rules": ["abnormal_lab_trends", "unusual_access"]
},
"sink": ["REALTIME_ANALYTICS_STORE", "ALERTING_SERVICE"]
}
}
}
This pattern supports a robust data platform where historical analyses benefit from batch processing while real-time operational needs are addressed through streaming. Teams can implement lineage and reconciliation checks to maintain consistency across the two paths, ensuring that the real-time results align with the batch-derived truths. The exact balance between batch and streaming will depend on data sources, regulatory constraints, the required time-to-insight, and the organization’s risk tolerance and maturity.
FAQ
How is batch processing different from streaming processing?
Batch processing aggregates data over a defined window and performs computations on the entire batch, prioritizing throughput and deterministic results, while streaming processes data as it arrives, delivering low-latency insights and continuous updates; in healthcare, batch is often used for historical reporting and data consolidation, whereas streaming supports real-time monitoring and alerting.
What factors should guide a healthcare data integration project when choosing between batch and streaming?
Key factors include required time-to-insight, data velocity, tolerance for latency, regulatory and auditing needs, data quality and lineage requirements, and the available operational maturity and budget for managing complex streaming infrastructures alongside batch pipelines.
Can batch processes feed streaming systems, or can streams be reconstituted into batch workloads?
Yes. Batch data can be re-ingested into streaming platforms through change data capture or periodic replays to seed real-time dashboards, and streaming data can be reconstituted into batch workloads by windowing or taking snapshots at regular intervals for historical analysis; hybrid architectures explicitly support these cross-path data flows.
What are common technologies used for batch processing?
Common technologies include Hadoop-based ecosystems (MapReduce, Hive, Pig), Spark in batch mode, traditional ETL tools, and data warehouse solutions that support scheduled, repeatable transformations; these tools emphasize scalability, reproducibility, and governance for long-running or periodic jobs.
What are common technologies used for streaming processing?
Common technologies include Apache Kafka for durable event transport, Apache Flink for stateful stream processing, Spark Structured Streaming, and cloud-based streaming services that provide low-latency ingestion and processing; these tools enable real-time analytics, alerting, and continuous decision support.