Now Reading: Edge AI vs Cloud AI: Where Should Intelligence Live?
-
01
Edge AI vs Cloud AI: Where Should Intelligence Live?


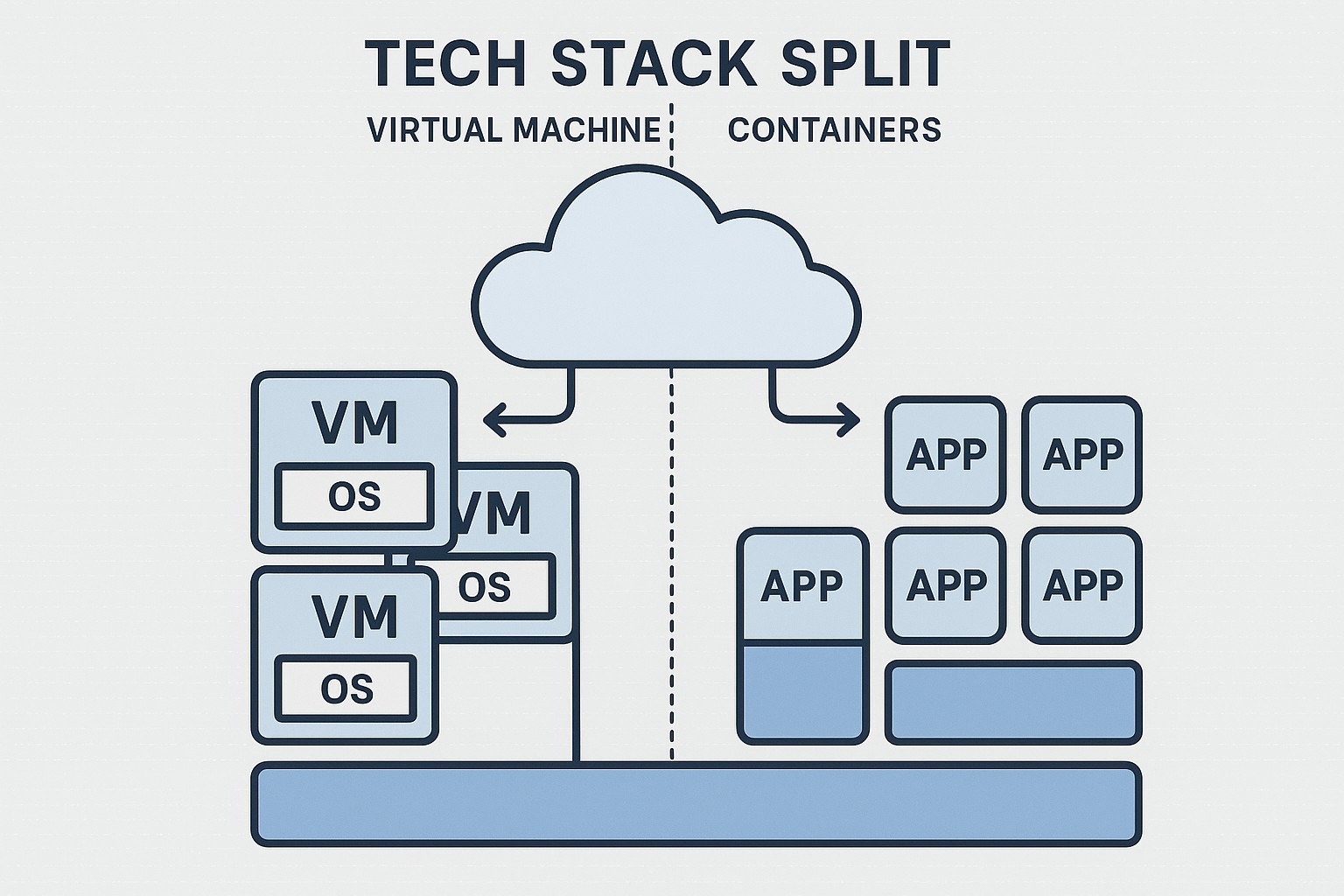
Edge AI: Decentralized Intelligence at the Edge
Edge AI describes running AI inference and, in some cases, lightweight training near the data source — on devices, gateways, or within local networks. It reduces the need to send raw data to centralized data centers, enabling real-time responses and preserving bandwidth for the most critical tasks. Advances in on-device accelerators, compact model architectures, and efficient runtimes have made this approach practical for a growing set of workloads—from sensor-driven anomaly detection on manufacturing lines to computer vision on mobile devices. The integration of edge computing with AI is reshaping product design, because latency and connectivity constraints increasingly influence where and how intelligence should be executed. In many scenarios, the combination of 5G connectivity and edge computing enables devices to share insights with nearby nodes without sending everything to the cloud, while still benefiting from centralized updates and governance when needed.
Edge AI also brings a set of practical considerations that influence deployment strategy. Teams must assess device capabilities, energy budgets, and the need for offline operation. The landscape of models is evolving toward smaller, more efficient architectures that can fit within constrained hardware while delivering acceptable accuracy. At the same time, orchestration across fleets of devices, firmware updates, and secure model delivery require robust management layers. Organizations often pursue a layered approach: lightweight inference on-device for immediate responses, with occasional synchronization to a distributed edge or central cloud for training, re-evaluation, and policy updates.
- Low-latency inference enabling real-time control and responsive user experiences
- Bandwidth savings by local filtering, summarization, and pre-processing of data
- Improved privacy by keeping sensitive data on-device or within a bounded local network
- Resilience and offline operation in environments with intermittent connectivity
Cloud AI: Centralized Power for Scale and Learning
Cloud AI leverages vast compute resources, scalable storage, and centralized data access to train larger models and run heavy inference workloads. It’s well suited for data aggregation, long-range analytics, and global synchronization of insights. Cloud platforms provide managed services, MLops pipelines, and robust security features, enabling teams to ship AI capabilities rapidly and repeatedly. The cloud is where experimentation and continuous learning happen most efficiently, with access to high-end GPUs, TPUs, and specialized accelerators, along with tooling for model training, evaluation, versioning, and governance. For organizations that need to monetize data, gain cross-domain insights, or deploy rapidly across large, distributed populations, cloud AI offers a scalable backbone that can support diverse use cases from marketing analytics to predictive maintenance at scale.
However, cloud-centric architectures depend on reliable networks and may incur data transfer costs and privacy considerations. Latency to the data center can be a bottleneck for real-time needs, and regulatory or governance requirements might constrain what data can be processed in the cloud or how it can be stored. For many teams, hybrid patterns that blend cloud learning with edge inference or on-device adaptation provide a practical compromise—allowing models to be trained and iterated in the cloud while delivering fast, localized inference on the edge.
Technical Factors: Latency, Bandwidth, Privacy, and Reliability
Latency is a primary constraint that often drives the choice between edge and cloud deployment. Edge processing reduces round-trip time and enables immediate reactions in control loops, robotics, wearables, and autonomous devices. Cloud-based inference introduces additional delays associated with network access, queuing, and remote processing, which can be acceptable for dashboards, batch analytics, or non-critical tasks but not ideal for time-sensitive operations. The acceptable latency threshold is highly application-specific and may dictate a hybrid strategy where critical decisions happen at the edge while the cloud handles non-urgent insights and model improvements.
Bandwidth and operational costs shape data flows. Transmitting high-volume sensor streams to the cloud can be expensive and impractical, especially in remote or bandwidth-constrained environments. Edge processing can perform feature extraction, compression, or summarization before sending signals to the cloud, thereby reducing transmission loads. Privacy and data sovereignty considerations also push organizations toward local data handling or federated approaches, where raw data remains on devices or within a regional boundary while only model updates or abstracted insights are shared with central services.
- Latency requirements and real-time constraints
- Data sensitivity, privacy, and regulatory compliance
- Available bandwidth, data volume, and cost of transmission
- Hardware, energy, and maintenance costs for edge devices versus cloud resources
Architecture Patterns and Data Flows
There is a spectrum of architectural patterns for deploying AI across edge and cloud, and the best choice often depends on the specific application, geography, and data governance model. A common pattern is on-device inference, where lightweight models run directly on the device, supported by an over-the-air (OTA) update mechanism to refresh models and configurations. Another frequent pattern is edge gateway orchestration, in which a local gateway aggregates data from multiple devices, performs intermediate processing, and forwards only relevant signals to the cloud for deeper analysis or training. For workloads that require heavy computation or centralized governance, cloud-centric inference and model lifecycle management operate as the primary brain, with distilled signals pushed back to the edge for deployment and real-time reaction.
Hybrid pipelines pair the strengths of edge and cloud in a coordinated flow. In such setups, raw data may be kept locally or summarized near the source, then sent to the cloud for training, improvement, and policy updates. Federated learning and secure aggregation enable model improvements across devices without exposing raw data to a central repository. Enterprises often use edge gateways to implement local inference markets, streaming analytics, and anomaly detection, while maintaining a cloud-based MLops stack for experimentation, version control, monitoring, and governance. The architectural choice frequently reflects privacy, compliance, availability, and the strategic importance of data as an enterprise asset, along with the resilience requirements of the deployment site.
Use Cases and Decision Guide: Where to Deploy Edge vs Cloud
In industrial settings, edge AI shines on factory floors where latency is critical for robotic arms, autonomous tooling, and quality inspection systems. Edge devices can run inference in real-time, detect anomalies, and trigger immediate actions without waiting for cloud feedback. In consumer electronics and mobile experiences, edge AI supports offline capabilities and privacy-preserving features, enabling responsive apps even in areas with spotty connectivity. Enterprises that operate across dispersed locations—such as retail, utilities, and transportation—often combine edge processing at sites with cloud analytics for fleet-wide optimization and long-term forecasting. The 5G era amplifies these dynamics by offering higher bandwidth and lower latency to support edge-to-edge collaboration, MEC-hosted services, and more reliable connectivity in mobile and fixed networks. This combination of edge intelligence and robust connectivity shapes how organizations approach data strategy, model maintenance, and deployment velocity for IoT initiatives.
When deciding where to deploy, consider the following framework. First, map latency requirements to the appropriate layer (edge for real-time needs, cloud for non-time-critical analysis and training). Second, assess data privacy and regulatory constraints to determine whether data can be processed in the cloud or must remain on-premises or on-device. Third, evaluate data volume and bandwidth costs to decide if local preprocessing or selective streaming is favored. Finally, align with organizational capabilities for model governance, OTA updates, and security—ensuring that the selected architecture supports ongoing improvement through testing, monitoring, and compliant data handling.
Implementation Patterns and Practical Considerations
Implementing edge and cloud AI requires careful planning around hardware selection, software stacks, and operational processes. Edge devices should balance compute power, energy efficiency, and form factor with the required AI model complexity. Software stacks must support model deployment, versioning, secure boot, and remote updates. In the cloud, teams should establish end-to-end MLops practices, including data versioning, experiment tracking, model governance, and robust monitoring. Across both layers, security must be embedded into the design—secure boot, attestation, encrypted data at rest and in transit, and resilient OTA update mechanisms. A disciplined approach to testing, documentation, and change management helps prevent drift between edge deployments and cloud models, ensuring consistent performance and compliance over time.
- On-device inference with occasional cloud synchronization for updates and training data
- Edge gateway orchestration for local aggregation, pre-processing, and policy enforcement
- Cloud-centric training, evaluation, and global deployment with controlled rollouts to edge devices
FAQ
What is edge AI?
Edge AI is the practice of running AI inference and, in some cases, lightweight training near the data source—on devices, gateways, or local networks—so decisions can be made quickly without sending all data to a centralized cloud. This approach reduces latency, conserves bandwidth, and often enhances privacy by keeping sensitive information closer to where it’s generated.
When should I use edge AI vs cloud AI?
The decision depends on latency requirements, data sensitivity, bandwidth costs, and hardware constraints. Edge AI excels when real-time decisions are essential or connectivity is unreliable, while cloud AI is advantageous for heavy training, cross-site data analysis, and scalable governance. In many cases, a hybrid pattern—edge inference for real-time tasks and cloud learning for model improvement—delivers the best of both worlds.
How does 5G influence edge AI and IoT deployments?
5G provides higher bandwidth, lower latency, and more reliable connectivity, which broadens the feasible scope of edge computing and enables more devices to participate in real-time collaborative workloads. It also supports MEC (multi-access edge computing) where processing happens at network edges, further reducing latency and enabling faster updates. However, effective deployments still require careful data governance and privacy considerations, especially when moving models or updates across networks.
What are common architectural patterns for hybrid edge-cloud AI?
Common patterns include on-device inference with cloud-backed model updates, edge gateways that collect and pre-process data before sending signals to the cloud, and federated learning where multiple devices collaboratively train a shared model without exchanging raw data. Hybrid pipelines also use cloud resources for heavy training and then push compact, optimized models to the edge for fast inference and offline operation.
What security considerations are essential for edge deployments?
Security essentials include secure boot and device attestation to ensure hardware integrity, encryption of data at rest and in transit, robust key management, and authenticated OTA updates to prevent tampering. Additionally, governance around data handling, access controls, and continuous monitoring help detect anomalies and adapt protections as the threat landscape evolves across distributed edge environments.
?")