Now Reading: Microservices vs Serverless: Choosing the Right Architecture
-
01
Microservices vs Serverless: Choosing the Right Architecture


Overview: Microservices versus Serverless in practice
In modern software architecture, microservices and serverless are often presented as competing patterns, yet many successful implementations blend both to fit specific business needs. Microservices describe a design where an application is decomposed into loosely coupled, independently deployable services that own their own data and run in containers or virtual machines. Serverless, by contrast, emphasizes a cloud-managed execution model where developers deploy small units of work—functions or event-driven processes—that run on managed runtimes with automatic scaling. Both approaches aim to improve agility, resilience, and time-to-market, but they do so with different operational assumptions and trade-offs.
For executives and engineers alike, the decision often comes down to how a system will be deployed, scaled, and governed in production, not merely how it is coded. Microservices are powerful for organizations that want explicit ownership boundaries, polyglot technology stacks, and strong control over deployment pipelines. Serverless is attractive when the focus is on rapid experimentation, event-driven automation, and offloading operational burden to a cloud provider. Understanding where each pattern shines—and where it may introduce friction—helps teams align architecture with business priorities, including time-to-value, cost predictability, and risk management.
Throughout this article we’ll compare the two approaches in terms of architecture, deployment, operations, cost, and migration considerations. The goal is to provide a practical framework for choosing microservices, serverless, or a hybrid path that leverages the strengths of both. When we mention the phrase microservices vs monolith, we’re highlighting how small, independently scalable components contrast with a single, tightly coupled codebase. The right decision depends on context: domain complexity, team organization, data strategy, and the acceptable level of infra management.
Architectural fundamentals: what makes microservices different from serverless
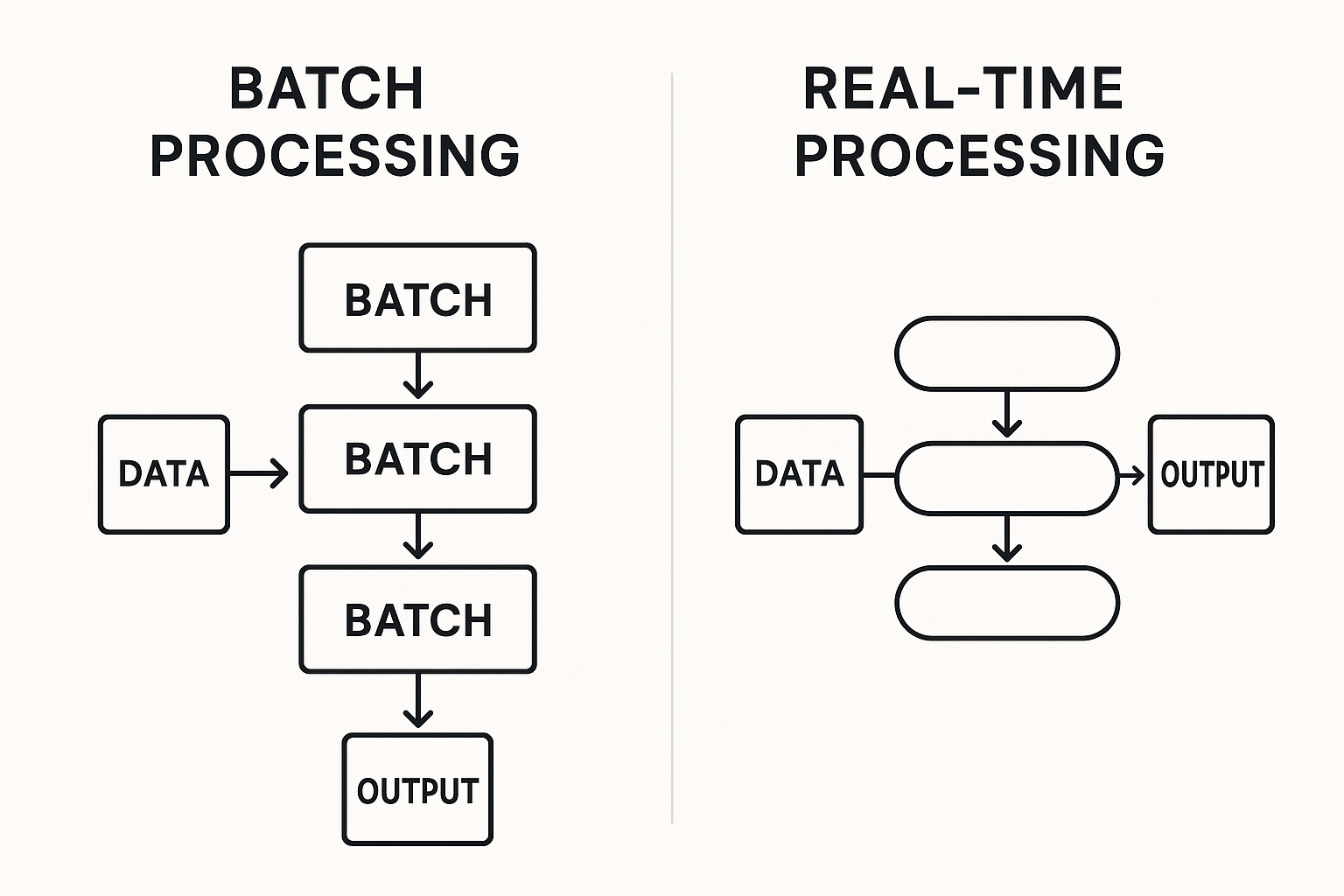
At a high level, microservices emphasize decomposition with explicit boundaries. Each service owns its own data, has a bounded context, and communicates with other services through lightweight APIs. This approach enables autonomous teams, more granular scalability, and the ability to upgrade or rewrite components with limited blast radius. Serverless, on the other hand, abstracts away server provisioning and capacity planning. You write small units of logic, wire them to events or HTTP endpoints, and rely on the platform to handle provisioning, routing, and fault tolerance.
In practice, many organizations adopt both patterns within the same portfolio. A typical arrangement might use microservices for business capabilities that require strong domain boundaries and long-lived state, while leveraging serverless for lightweight, event-driven tasks such as image processing, data enrichment, or scheduled analytics. This hybrid approach often yields a balance between autonomy and operational simplicity, allowing teams to optimize for speed without sacrificing control where it matters most.
Deployment and scaling characteristics: how each pattern behaves in production
The deployment model and scaling behavior of microservices and serverless differ in meaningful ways, and these differences influence performance characteristics, reliability, and cost. Microservices deployments usually run in containers or VMs within a managed cluster. Each service can be scaled independently, and you typically configure deployment pipelines, service meshes, and observability tooling to manage traffic, retries, and outages. Serverless deployments are driven by events and on-demand execution, with most capacity and placement decisions handled by the cloud provider. This can dramatically reduce the maintenance burden but also introduces uncertainties around latency, cold starts, and vendor lock-in.
For teams, the practical consequences are clear: microservices offer predictable performance and fine-grained control at the cost of more complex operations. Serverless offers rapid iteration and lower upfront operational risk but may require rethinking latency budgets and data access patterns. The choice often hinges on specific workloads, required SLAs, and how much operational work the organization is prepared to absorb. Below is a concise framework to think through scaling decisions in practice.
- Understand scaling granularity: Microservices scale at the boundary of a service; serverless scales automatically per function invocation and can lead to unpredictable latency when cold starts occur.
- Evaluate latency and throughput requirements: If your workload demands consistent, low-latency responses, microservices running on dedicated infrastructure may be preferable; serverless excels when bursty loads are common and the latency tolerance is higher.
- Plan for state management and data locality: Microservices often require carefully designed data ownership and boundaries; serverless functions should avoid long-running state and rely on external storage or services, keeping state external and transient.
- Anticipate operational implications: Microservices require observability, tracing, and distributed tracing across services; serverless shifts much of that burden toward the platform but introduces cold-start and lifecycle considerations that your team must address in architecture and testing.
Key characteristics to consider in practice include startup latency, cold starts, invocation concurrency, and the cost model. Microservices can incur ongoing compute and orchestration costs based on sustained utilization, while serverless billing often depends on execution time and memory usage, with occasional spikes that complicate budgeting. If an application consists of many small, event-driven tasks, serverless can be a natural fit. If the workload requires long-running processes with consistent load, microservices provide more predictable performance and cost control. When both patterns are used together, the system can route appropriate workloads to the most suitable execution model, aligning with business requirements and technical constraints.
Operational and DevOps considerations: observability, reliability, and governance
Operating a microservices ecosystem introduces challenges around service discovery, network reliability, and end-to-end tracing. Teams must invest in standardized contracts, versioning strategies, and automated testing across service boundaries. Governance becomes critical as the number of services grows, and consistent security, compliance, and data-handling practices must be enforced across many independent components. Serverless shifts much of the operational burden toward the cloud provider, but it also requires careful attention to permissions, event schemas, and monitoring of pay-per-use costs. Both patterns demand strong CI/CD pipelines, robust incident response plans, and comprehensive observability to understand how parts of the system interact in production.
Observability is notably different in the two models. In microservices, you rely on distributed tracing, log correlation, and metrics across services. In serverless environments, you need to correlate function invocations, event sources, and downstream processes, which can be more challenging when functions are ephemeral. Both patterns benefit from standardized runtime contracts, centralized logging, and a unified dashboard for health and performance. Security considerations run in parallel: microservices require consistent API security, mutual TLS where appropriate, and data governance across services; serverless requires strict IAM policies, resource-based permissions, and careful configuration of event triggers and function roles.
Cost and ROI considerations: budgeting for a mixed architecture
Cost modeling is one of the most practical aspects of choosing between microservices and serverless. With microservices, you typically pay for predictable infrastructure, container runtimes, and orchestration, plus the costs of development and operations teams maintaining the platform. Serverless often promises lower operational overhead and a pay-as-you-go model, but sometimes leads to unpredictable bills at scale, depending on invocation volume, memory usage, and execution duration. A blended approach can offer a balanced cost profile: move steady-state, long-running, or heavy-latency components to microservices, and offload bursty, event-driven tasks to serverless.
To make a rational ROI assessment, teams should consider not only direct cloud charges but also the total cost of ownership, including development velocity, platform complexity, and the risk of vendor lock-in. In some contexts, the speed of experimentation enabled by serverless can shorten time-to-market for new features, which translates into revenue impact that offsets higher per-unit costs. In others, the stability and predictability of microservices-based systems provide cost savings through reduced outages and improved ability to forecast capacity and cost over time. A careful, scenario-based budgeting exercise that accounts for latency requirements, reliability targets, and organizational capabilities usually yields the most accurate picture.
Migration and platform fit: a practical path to the right architecture
Your starting point and target end state matter greatly when choosing between microservices, serverless, or a hybrid approach. Organizations that begin with a monolith often face questions about domain boundaries, data coupling, and rollout risk. A staged migration typically begins with identifying autonomous capabilities that can be extracted as standalone services, or tasks that can be expressed as serverless functions with well-defined event triggers. As teams gain experience, they may extend the decomposition to more domains, gradually moving toward a combination that aligns with team structure and business needs.
Deciding whether to pivot a monolithic application toward microservices or to embrace serverless for specific components requires careful planning around data ownership, API contracts, and deployment pipelines. In many cases, a hybrid approach offers the best of both worlds: core business services may run as microservices with designated data stores, while peripheral workloads—such as image transformation, notification dispatch, or real-time analytics—are implemented as serverless functions. The migration plan should include a clear scope, a risk assessment, milestones for automated testing and integration, and a governance model that defines security, compliance, and cost controls across the new architecture.
- Define the domain boundaries and assign ownership for each service to minimize cross-team friction.
- Map data boundaries early, ensuring each service has clear access to the data it owns or operates on, to avoid tight coupling.
- Establish a pragmatic migration plan with incremental milestones, observable metrics, and rollback capabilities in case of integration challenges.
Practical decision framework: when to choose what, and how to mix
There is no one-size-fits-all answer. The most effective architectures often combine patterns to suit business goals, technical constraints, and organizational realities. A practical framework focuses on four dimensions: workload characteristics, team capabilities, data strategy, and risk tolerance. Workload characteristics cover predictability, latency sensitivity, and event-driven behavior. Team capabilities encompass domain knowledge, DevOps maturity, and experience with distributed systems. Data strategy includes ownership, consistency requirements, and integration with legacy systems. Risk tolerance reflects concerns about vendor lock-in, security exposure, and control over infrastructure.
With these dimensions in mind, teams can design a pragmatic path forward. For example, a face-paced product team with small, autonomous squads may prefer serverless for rapid feature delivery and a lightweight ops footprint, while critical services with strict latency requirements and complex transactional integrity may benefit from microservices deployed on a managed cluster. A shared governance model, standardized contracts, and a clear decision trail help maintain consistency as the architecture evolves. The goal is to enable business agility without sacrificing reliability or cost control.
FAQ
Below are common questions teams ask when deciding between microservices and serverless, along with concise guidance to help with planning and implementation.
What is the biggest advantage of microservices over serverless?
The strongest case for microservices is explicit control over deployment boundaries, data ownership, and runtime characteristics. This can translate into more predictable latency, easier enforcement of domain boundaries, and stronger governance for long-lived, stateful services. If your organization requires granular autonomy for teams and operates complex, stateful workloads with steady demand, microservices can provide a sustainable foundation.
When is serverless the better fit?
Serverless excels when workloads are highly event-driven, irregular, or bursty, and when the operational burden of managing infrastructure needs to be minimized. If your primary goals include accelerating experimentation, reducing time-to-value for new features, and limiting ongoing maintenance chores, serverless can offer significant advantages—provided you design around cold starts, vendor capabilities, and cost estimation for high-usage scenarios.
Can you mix microservices and serverless effectively?
Yes. A hybrid approach often yields the best balance: use microservices for core, long-lived services with stable load and strict data governance; offload discrete, stateless, event-driven tasks to serverless. The key is to establish clear interfaces, consistent security policies, and robust observability so teams can reason about behavior across both models. With careful planning, a mixed architecture can deliver agility without sacrificing reliability.
What are the major risks to watch when migrating from monoliths?
Major risks include data coupling across services, insufficient boundary definitions leading to tight coupling, and orchestration complexity that can erode team autonomy. There is also the danger of creeping operational overhead if the number of services grows too quickly without adequate governance. A phased migration with measurable milestones, strong API contracts, and a focus on domain-driven design helps mitigate these risks while letting you learn and adapt throughout the process.
How should I measure success after a pattern switch?
Define concrete metrics tied to business outcomes and technical objectives, such as deployment frequency, lead time for changes, service-level performance, reliability, cost per transaction, and time-to-market for new capabilities. Regular reviews to assess observability coverage, error budgets, and incident learnings are essential for validating that the chosen pattern delivers the intended value and for guiding future adjustments.