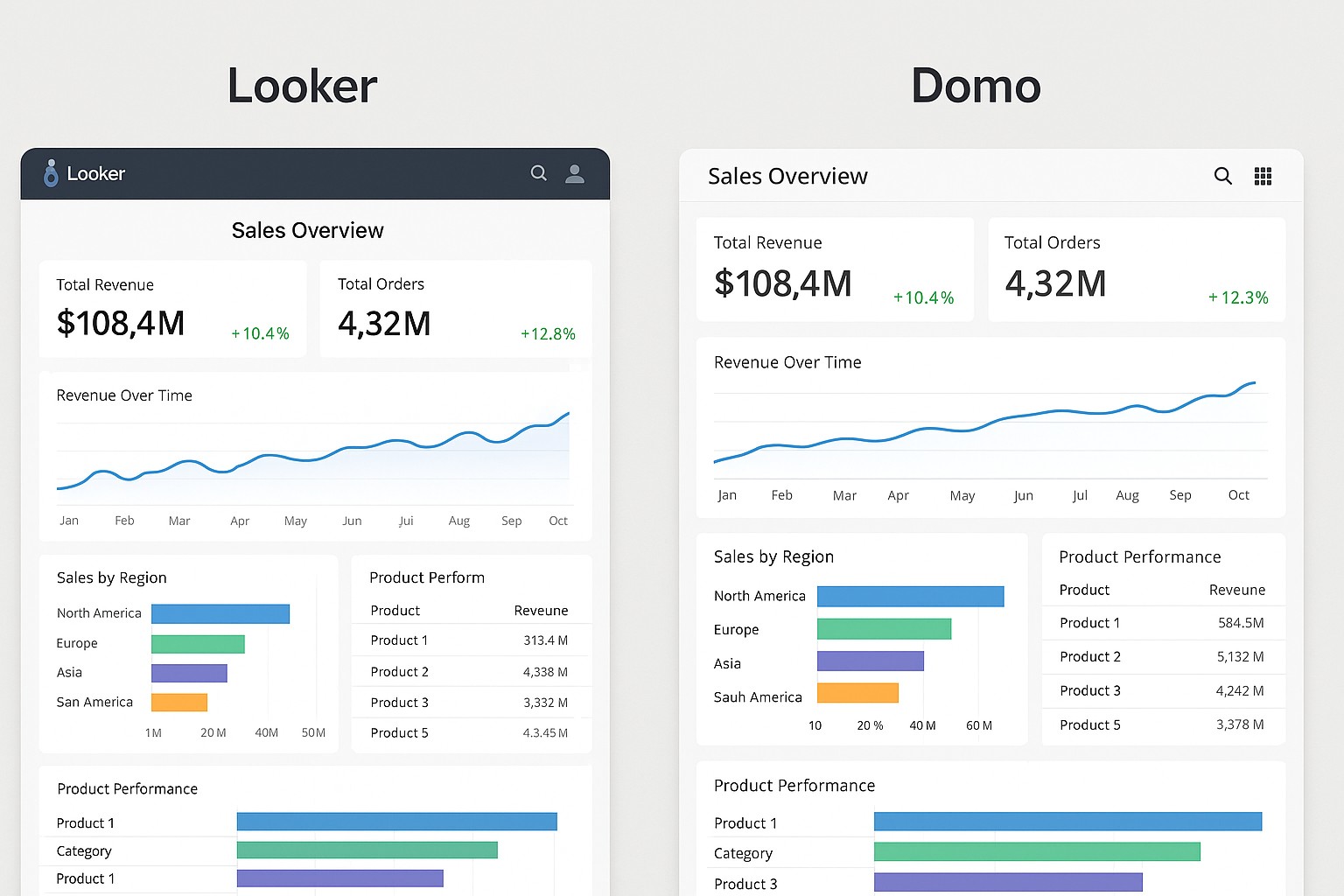
Now Reading: ChatGPT vs Bard vs Copilot: Which AI Chatbot Reigns Supreme?
-
01
ChatGPT vs Bard vs Copilot: Which AI Chatbot Reigns Supreme?


Market landscape and the players you should know
In enterprise AI today, organizations evaluating conversational AI and developer tooling encounter a diverse landscape shaped by use-case demands, governance requirements, and deployment constraints. ChatGPT from OpenAI has established itself as a benchmark for natural language generation, offering broad conversational fluency, instructive prompts, and a flexible API that supports a wide range of business scenarios. Google Bard emphasizes access to current information and retrieval-augmented generation, positioning itself as a tool for research, fact-based briefing, and knowledge discovery. GitHub Copilot acts as a specialized coding assistant tightly integrated into developers’ IDEs, aiming to accelerate software delivery and lower the barrier to learning new frameworks. Perplexity presents itself as a consumer-grade, reasoning-oriented assistant that prioritizes source-aware responses and transparent explanations, making it appealing for rapid research and structured answer generation. Taken together, these tools influence how teams approach content creation, customer engagement, software development, and decision support in ways that are complementary as much as competitive.
For decision-makers, the landscape is less about declaring a single winner and more about mapping capabilities to business processes, data governance policies, and organizational maturity. Organizations increasingly pursue multi-tool strategies where a chatbot handles front-dline customer interactions and knowledge retrieval, Copilot drives code generation and code reviews, while Bard or Perplexity can support rapid research briefs or executive summaries. The resulting ecosystem requires careful alignment of data stewardship, security controls, cost management, and measurable outcomes. As the market matures, vendors are expanding governance features, expanding regional data residency options, and offering enterprise-grade SLAs to meet regulatory demands in sectors such as finance, healthcare, and manufacturing.
Beyond product features, effective adoption hinges on a governance-first approach: defining who can prompt, what data can be shared, how outputs are reviewed, and how results are integrated into downstream systems. The strongest transformational outcomes arise when organizations standardize on sensible prompt design practices, establish clear escalation paths for high-risk outputs, and couple AI capabilities with human-in-the-loop workflows that preserve accountability. In short, the modern AI toolbox for enterprises is less about choosing a single best tool and more about orchestrating a portfolio that aligns with business goals, risk tolerance, and engineering discipline.
Core capabilities across language generation and reasoning
All four platforms share a common baseline set of capabilities: robust natural language understanding, prompt orchestration, and the ability to generate meaningful, actionable outputs. Yet the emphasis and optimization vary. ChatGPT prioritizes conversational fluency, long-context reasoning, and flexible instruction following, making it well-suited for drafting documents, composing communications, and supporting knowledge workers with creative tasks. Bard emphasizes retrieval-augmented generation with a focus on bringing fresh information into responses, which is valuable for research briefs, market updates, and decision-support scenarios that demand current data. Copilot centers on code synthesis, API-driven guidance, and context-aware suggestions within developer environments, enabling faster implementation cycles and learning of new languages. Perplexity combines reasoning with source-aware responses, aiming to deliver transparent conclusions and verifiable references. The practical consequence is that teams should map the intended output type—creative writing, factual summaries, real-time data retrieval, or code generation—to the most suitable platform, or to a carefully designed blend of platforms.
From a technical perspective, these systems rely on transformer architectures, large-scale pretraining, and fine-tuning strategies that emphasize instruction-following and conversational alignment. They diverge in how they access external knowledge, manage session memory, and integrate with enterprise data. Copilot’s strengths lie in IDE-level integration, language-agnostic code assistance, and secure handling of code assets, while Bard’s value proposition hinges on live web data access and citation capabilities for timely answers. ChatGPT and Perplexity focus on dialog-based workflows, content synthesis, and structured prompts that can be embedded in knowledge bases and customer-support channels. For organizations, the key takeaway is to understand the data contracts, data provenance, and control surfaces each platform provides, and to design usage patterns that minimize risk while maximizing output quality and speed.
ChatGPT: Strengths, limitations, and typical use cases
ChatGPT’s strengths lie in natural language fluency, adaptability across domains, and the ability to structure outputs with clear formatting, sections, and steps. It excels at drafting proposals, creating templates, summarizing long documents, and assisting knowledge workers with ideation and planning. In customer-support workflows, it can triage inquiries, draft response drafts for human agents, and support knowledge-base augmentation. However, limitations include the possibility of hallucinations, outdated knowledge beyond the training cutoff, and sensitivity to prompt specificity. Enterprises counter these risks by applying guardrails, restricting data that can be shared with the model, and enforcing human-in-the-loop reviews for high-stakes outputs.
In practice, organizations often deploy ChatGPT as a versatile assistant for internal content production, policy drafting, and training material generation. When used in customer-facing contexts, it is common to implement an escalation pathway to human agents for cases that require nuanced judgment or sensitive information. For technical teams, ChatGPT can assist with drafting API wrappers, outlining architectural diagrams, and generating test plans, provided that prompts are carefully constrained and outputs reviewed by engineers. The cost and performance considerations depend on usage patterns, the desired response length, and the degree of customization required to align responses with brand voice and governance policies.
Google Bard: Strengths, limitations, and typical use cases
Bard’s strengths center on up-to-date information access, citation-rich answers, and retrieval-augmented generation. It is well-suited for competitive intelligence briefs, market research summaries, and quick exploratory queries where current web data enhances decision-making. Use cases include drafting current-market analyses, producing briefing documents for meetings, and assisting researchers who need quick synthesis with source links. Limitations include variability in answer quality, dependence on live data feeds that may introduce latency, and the need for rigorous verification in high-stakes environments. Teams often pair Bard with internal knowledge bases to ensure consistency and to catch any discrepancies between external data and internal guidance.
From an operational standpoint, Bard can support fast-paced inquiry workflows, product discovery sessions, and real-time reporting tasks where freshness matters. For governance-minded organizations, it is important to implement data-handling policies, manage data exchange with external services, and set expectations for citation reliability. Bard’s ecosystem advantages also include strong integration points with Google Cloud tooling, which can simplify authentication, data access governance, and monitoring for large-scale enterprise deployments.
GitHub Copilot: Strengths, limitations, and typical use cases
Copilot’s core advantage is accelerating software development through natural-language prompts that translate into code, comments, or API usage. It is particularly effective for boilerplate tasks, repetitive patterns, and exploring multiple implementation approaches. In practice, teams use Copilot to reduce time-to-first-pass, learn new libraries, and generate test scaffolding. However, risks include the potential for incorrect or insecure code, reliance on training data that may include copyrighted or proprietary examples, and limitations in support for less common languages or domain-specific frameworks. To mitigate these risks, most enterprises implement strict code review guidelines, security checks, and prompts that remind users to verify logic and security implications before merging.
Copilot shines when integrated into a modern IDE, with context-aware suggestions that align with project structure and dependencies. It also enables developers to experiment with alternative implementations, which can speed up prototyping and knowledge transfer within teams. For organizations, governance considerations around data sharing, prompt privacy, and retention policies are crucial, since code snippets and project information may traverse the external service during generation and caching. When used responsibly, Copilot becomes a force multiplier for developers, reducing mundane tasks and enabling engineers to focus on higher-value design and reasoning tasks.
Perplexity and other challengers: strengths, limitations, and typical use cases
Perplexity emphasizes reasoning, transparency, and source-aware responses, which appeals to users who want traceable conclusions and explicit references. It can be effective for quick research, structured summaries, and stepwise problem solving in domains where clear justification matters. Limitations include variability in depth of knowledge, potential dependence on external data sources with inconsistent coverage, and the need for verification in specialized or highly regulated sectors. Perplexity tends to perform well in education, product research, and analytical tasks where a clear link to sources enhances credibility. Enterprises leveraging Perplexity often pair it with internal knowledge graphs and data catalogs to improve relevance and control over content provenance.
In practical terms, Perplexity can supplement teams that require transparent answer trails, such as analysts preparing executive summaries or researchers assembling literature reviews. When combined with other tools that provide enforcement of governance rules and content moderation, Perplexity becomes part of a layered approach to information synthesis that balances speed and reliability. As with any tool in this space, the most effective deployments use Perplexity in conjunction with human oversight and rigorous verification practices.
Data, safety, and privacy considerations
Organizations evaluating these tools should assess how data is processed, stored, and potentially used for model training. Enterprise offerings typically provide options to restrict data sharing, delete user content, and enforce data residency requirements. Guardrails, content filtering, and access controls help mitigate leakage and ensure compliance with industry standards. However, no system is flawless; governance frameworks should include risk assessments, usage policies, and escalation paths for sensitive inquiries. Privacy-by-design practices—such as minimizing data exposure, redaction where possible, and clear workflows for confidential material—are essential when deploying these tools at scale. Additionally, organizations should define data ownership for generated outputs, establish retention schedules, and implement monitoring to detect anomalous prompts or data exfiltration attempts.
Beyond compliance, it is important to consider the long-tail data governance implications. For example, prompts that echo proprietary workflows, customer data, or confidential business metrics may create third-party exposure if not adequately protected. Enterprises commonly adopt a layered approach: isolate sensitive workloads, use mentor-guarded templates for prompts, and store sensitive prompts only in systems that are audited and governed under enterprise agreements. Training data usage policies—whether the vendor allows or restricts learning from customer content—directly influence how organizations architect experiments and pilots. In practice, successful risk management combines technical safeguards with organizational processes, including regular security reviews, incident simulations, and a clearly defined data lifecycle for generated content.
Integration, ecosystems, and deployment considerations
The value of these tools increases significantly when they interoperate with existing stacks, data warehouses, and business processes. Copilot integrates deeply into developer workflows via IDEs, enabling real-time code generation, API usage examples, and context-preserving suggestions throughout the coding lifecycle. ChatGPT and Bard can be embedded in chat interfaces, customer-support portals, and knowledge bases, typically connected to enterprise authentication and governance layers to enforce access control and data policies. Perplexity serves as a flexible retrieval-backed assistant that can augment search pipelines, knowledge graphs, and research workflows with explainable results. A thoughtful deployment strategy should address data ingress, access patterns, caching behavior, and scalable hosting—whether in cloud environments or on-premises—to meet latency, reliability, and regulatory requirements. Interoperability with identity providers, auditing, and incident response tooling is critical for regulated environments.
From an architectural standpoint, teams should design integration patterns that support modularity and swap-ability. For instance, a customer-support desk might route complex inquiries to ChatGPT-based agents for drafting replies, while fielding technical questions to Copilot-enabled developer assistants for internal tooling, with Bard or Perplexity providing supplementary, source-backed research. Such arrangements depend on robust API gateways, consistent data schemas, and well-defined service-level expectations. The overarching objective is to create a coherent ecosystem where outputs flow toward productive workflows, and where governance policies travel with data across tool boundaries, rather than becoming brittle silos.
Pricing, access, and enterprise considerations
Pricing models vary widely across these platforms, ranging from per-seat licensing to usage-based plans, and from consumer tiers to enterprise-grade agreements. ChatGPT typically offers usage-based pricing with enterprise options emphasizing data security and governance capabilities. Bard’s pricing strategy aligns with Google’s broader cloud ecosystem, often integrated with productivity tools and enterprise search features that can affect total cost of ownership. Copilot is usually positioned as a developer tool with tiered pricing based on seat counts and usage, including organization-wide controls for data sharing and compliance. Perplexity generally operates on a consumer-to-enterprise continuum, with value tied to response quality, latency, and access to sources. For businesses, a thorough cost assessment should consider long-term licensing, data-handling guarantees, and the potential downstream benefits of faster content creation, reduced context switching, and accelerated development cycles.
- Pricing models and total cost of ownership: evaluate per-seat versus usage-based costs, bulk discounts, and renewal terms.
- Data handling guarantees and compliance: examine data retention, training on customer data, and certifications (ISO, SOC 2, etc.).
- Access controls and identity integration: verify support for SSO, MFA, audit trails, and role-based access control.
- Ecosystem fit and governance: assess availability of connectors, SDKs, governance features, and monitoring capabilities.
Practical decision framework for teams
To choose among these tools, teams should apply a structured framework that accounts for use case, governance, and execution constraints. The framework below distills high-value criteria into actionable steps.
- Define primary use case and success metrics (e.g., content generation speed, coding productivity, or retrieval quality).
- Map data governance and privacy requirements to platform capabilities (data retention, sharing, redaction).
- Assess integration readiness (API coverage, SDKs, authentication, and alignment with existing tech stack).
- Evaluate latency, uptime, and service levels that match business processes and user expectations.
- Plan for human-in-the-loop workflows, escalation gates, and policy-driven review mechanisms to manage risk.
In practice, this framework guides pilots toward measurable outcomes, ensuring that the chosen tooling aligns with organizational risk appetite and technical feasibility. Organizations should also define a phased rollout plan that includes a sandbox period, a limited-usage pilot in a controlled department, and a broader deployment contingent on governance and security reviews. By formalizing these steps, teams reduce the likelihood of misalignment and increase the probability of delivering tangible value across content, development, and decision-support use cases.
Ethics, bias, and governance considerations
Ethical considerations and governance controls are essential when deploying these tools at scale. Bias in model outputs can arise from training data, prompt design, and the broader socio-technical context in which the tools operate. Organizations should implement bias-mitigation practices, content moderation guidelines, and transparent disclosure when outputs are used to influence decision-making. Governance should also cover accountability, model risk management, and clear owners for prompts, outputs, and data flows. In regulated industries, governance frameworks must articulate data handling standards, retention policies, and auditability of AI-assisted decisions. The goal is to balance innovation with responsibility, ensuring that AI outputs are accurate, traceable, and aligned with organizational values and legal requirements.
Practical governance also means establishing escalation paths for high-stakes outputs, maintaining an updated inventory of prompts and data sources, and instituting regular reviews of system performance and safety controls. Organizations benefit from a culture of continuous improvement, where teams document learnings from prompts, share guardrails across departments, and update policies in response to evolving regulatory guidance and user feedback. When these governance practices are embedded in the deployment lifecycle, AI capabilities become reliable, deployable components of business processes rather than ad-hoc experiments.
FAQ
How do ChatGPT, Bard, Copilot, and Perplexity differ in terms of core technology?
All four rely on transformer-based architectures with large-scale pretraining, but they differ in retrieval mechanisms, data sources, and integration depth. ChatGPT emphasizes conversational memory, instruction tuning, and API-driven customization for dialogue quality. Bard prioritizes live web access and citations to ground answers in current information. Copilot is tightly integrated into IDEs and trained on code repositories to generate and suggest code in context. Perplexity focuses on explainability and source-aware responses, aiming to provide verifiable reasoning. Enterprises should consider not only the model quality but also data contracts, licensing terms, and governance controls that govern how prompts and outputs are handled inside organizational boundaries.
Which tool is best for coding assistance?
GitHub Copilot is the most specialized for coding tasks, offering context-aware code generation, API usage examples, and boilerplate creation within the editor. It can significantly boost developer productivity, especially for repetitive patterns and familiar tech stacks. However, no tool should replace thorough code review, security checks, and testing. For non-coding tasks, other platforms can provide value, but for software development specifically, Copilot paired with solid governance, secure coding practices, and automated QA processes generally yields the strongest outcomes.
What are the data privacy implications when using these tools in enterprise settings?
Data privacy implications depend on deployment mode (cloud versus on-prem), data residency, and training data usage policies. Enterprise offerings typically provide controls to prevent sharing sensitive data with the model, options to delete or redact inputs, and assurances about whether customer data is used to train models. It is essential to review vendor compliance certifications, encryption standards, and access controls. Organizations should implement data handling policies, conduct risk assessments, and ensure auditability of AI-driven actions, particularly when outputs influence customer data or proprietary business processes.
Can these tools be integrated into existing enterprise software stacks?
Yes, many tools offer APIs, SDKs, and marketplace connectors that enable integration with customer relationship management systems, knowledge bases, ticketing platforms, and development environments. Before integration, teams should assess API rate limits, security requirements, identity management compatibility, and data governance policies. A successful integration plan includes monitoring, logging, and governance checks that ensure outputs align with internal standards and regulatory constraints while delivering measurable productivity gains.
What is the typical cost comparison across these platforms?
Cost varies with usage, feature sets, and contract terms. Copilot pricing typically centers on per-user or per-seat licensing with enterprise options, while ChatGPT’s enterprise offerings emphasize usage tiers and governance features. Bard’s cost considerations are tied to integration within Google Cloud and productivity tool bundles, which can affect total cost depending on existing footprints. Perplexity’s pricing tends to be consumer-aligned with enterprise options in some plans. A robust cost comparison should model total cost of ownership, including licensing, data-handling charges, integration and maintenance, and the value of accelerated output across teams.