Now Reading: Machine Learning: Algorithms, Applications, and Future Trends
-
01
Machine Learning: Algorithms, Applications, and Future Trends


Foundations of Machine Learning
Machine learning sits at the intersection of statistics, computer science, and domain knowledge, offering a data-driven approach to inference, prediction, and optimization. It reduces the need for explicit rule-based programming by allowing systems to learn patterns from historical data, adapt to new contexts, and improve over time as new information becomes available. In practice, organizations leverage ML to uncover insights, automate routine decision making, and support complex forecasting tasks in environments characterized by scale, noise, and uncertainty. The core challenge is to translate business objectives into observable signals that a model can learn from, while ensuring that the resulting solutions are robust, transparent, and aligned with governance requirements.
Foundational concepts such as data quality, feature representation, model capacity, and evaluation strategies shape the success of a machine learning project. Data quality encompasses completeness, accuracy, timeliness, and consistency, all of which influence model performance and reliability. Representation matters because how information is encoded can simplify or complicate the learning task, affecting generalization to unseen data. Model capacity determines whether a system can capture complex relationships without overfitting, and evaluation must consider not only accuracy but calibration, fairness, and operational impact. In mature settings, ML is complemented by robust data pipelines, versioning, monitoring, and governance practices that address security, privacy, and ethical concerns.
Core Algorithms
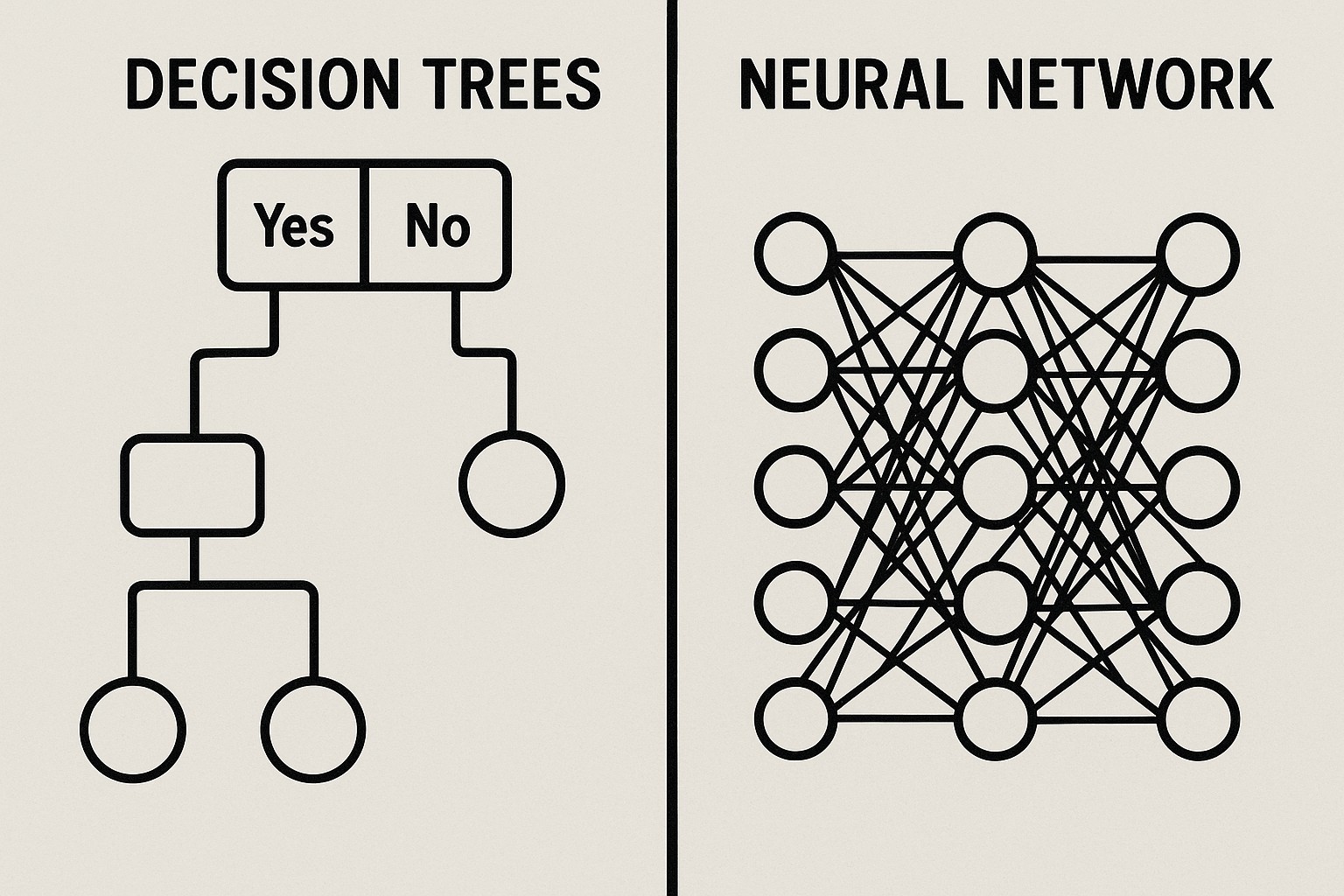
At a high level, machine learning algorithms fall into three broad families: supervised learning, unsupervised learning, and reinforcement learning. Supervised methods learn mappings from inputs to known outputs using labeled data, excelling in prediction and classification tasks when labeled examples are abundant. Unsupervised techniques discover structure in unlabeled data, supporting clustering, representation learning, and anomaly detection. Reinforcement learning optimizes sequential decision-making by training agents to maximize cumulated rewards through interaction with an environment. Most practical systems today combine these core ideas with specialized techniques to address specific problems, data regimes, and operational constraints. A solid understanding of these categories helps teams choose appropriate methods, set realistic expectations, and design flexible architectures that can evolve as data and requirements change.
- Linear and logistic regression
- Decision trees and random forests
- Support vector machines
- Neural networks and deep learning
- Ensemble methods (boosting, bagging)
- K-means clustering
- Principal component analysis
Beyond algorithm selection, practitioners focus on training paradigms, evaluation criteria, and deployment considerations. For supervised tasks, supervised learning objectives such as cross-entropy for classification or mean squared error for regression guide optimization, while regularization, cross-validation, and hyperparameter tuning guard against overfitting. Unsupervised learning emphasizes interpretability and stability of discovered structures, with metrics tailored to the chosen task. Reinforcement learning demands careful design of reward signals, exploration strategies, and safety constraints to balance long-term performance with short-term risk. Across all categories, a disciplined approach to data management, version control, and monitoring is essential to ensure models remain reliable as data evolves.
ML Project Lifecycle
Successful machine learning initiatives follow a structured lifecycle that begins with framing the business problem and ends with measured impact in production. This lifecycle emphasizes collaboration between data scientists, engineers, product owners, and stakeholders, ensuring that technical choices align with strategic goals, compliance standards, and user needs. Early stages focus on translating a vague objective into measurable success criteria, while later phases concentrate on data readiness, modeling, deployment, and ongoing governance. In practice, organizations adopt iterative loops that converge quickly on viable solutions, enabling rapid experimentation while maintaining control over risk and scalability.
- Define problem and success criteria: articulate the decision the model will support, the metrics that constitute success, and the constraints that apply in real-world use.
- Acquire and explore data: collect relevant data sources, assess quality, and perform initial exploratory analysis to identify patterns and potential biases.
- Clean, preprocess, and feature engineering: address missing values, outliers, and inconsistencies; derive informative features that improve learning signal.
- Model selection and training: choose appropriate algorithms, split data into training/validation/test sets, and tune hyperparameters for performance and robustness.
- Evaluation and validation: assess accuracy, calibration, fairness, latency, and resilience under distribution shifts; simulate real-world scenarios where possible.
- Deployment and integration: containerize models, integrate with existing systems, and establish monitoring, observability, and rollback plans.
- Governance, compliance, and iteration: implement governance frameworks, auditability, and continuous improvement loops that adapt to changing data and requirements.
In contemporary practice, successful projects blend model development with robust engineering: scalable data pipelines, automated testing, versioned artifacts, and reliable deployment processes. Operational considerations such as latency budgets, resource usage, and security monitoring drive architectural decisions, while governance concerns—privacy, bias mitigation, and accountability—shape how models are designed, evaluated, and updated over time. The lifecycle is not linear but iterative, with feedback from production informing refinements, data acquisition strategies, and business priorities.
Applications Across Industries
Machine learning is reshaping how organizations think about product design, risk management, customer experience, and supply chain agility. In environments characterized by large datasets, dynamic conditions, and complex interactions, ML enables more accurate forecasting, personalized recommendations, and automated decision making at scale. However, value realization requires careful alignment with domain knowledge, regulatory considerations, and thoughtful deployment strategies to avoid unintended consequences. Across industries, the most successful efforts couple technical excellence with clear executive sponsorship and rigorous measurement of business impact.
- Finance and banking: fraud detection, credit risk scoring, algorithmic trading, and customer analytics.
- Healthcare and life sciences: medical imaging, predictive diagnostics, drug discovery, and operational optimization.
- Manufacturing and supply chain: predictive maintenance, demand forecasting, quality control, and logistics optimization.
- Retail and e-commerce: demand sensing, dynamic pricing, recommendation engines, and customer segmentation.
- Transportation and logistics: route optimization, autonomous systems, demand forecasting, and fleet management.
- Energy and utilities: load forecasting, grid optimization, anomaly detection, and asset optimization.
- Agriculture and environmental science: yield prediction, precision agriculture, climate modeling, and biodiversity monitoring.
- Technology and telecommunications: network optimization, user behavior analytics, and security monitoring.
Beyond the industry-specific use cases, organizations increasingly invest in cross-cutting capabilities such as model governance, explainability, and responsible AI to build trust with customers, regulators, and internal stakeholders. The most impactful applications balance automation with human oversight, delivering outcomes that are efficient, fair, and adaptable to evolving business realities. A robust ML program also requires clear performance expectations, transparent models where possible, and a culture of continuous learning to stay ahead in a rapidly changing technological landscape.
Future Trends and Challenges
The future of machine learning is shaped by advances in general-purpose and foundation models, which promise broader capabilities and faster deployment of sophisticated AI systems. These developments expand the potential for transfer learning, multi-task reasoning, and synthetic data generation, enabling organizations to tackle complex problems with less task-specific customization. As models become more capable, the emphasis on responsible AI, model governance, and risk management intensifies, driving new standards for transparency, accountability, and safety. Edge AI and on-device inference are pushing intelligence closer to the user, reducing latency and preserving privacy by processing data locally where feasible. In parallel, interoperability and data stewardship practices will be critical to ensuring that models can responsibly leverage heterogeneous data sources across organizational boundaries.
However, substantial challenges accompany these trends. Data privacy and security remain paramount as data ecosystems grow more interconnected, and regulatory frameworks around bias, discrimination, and accountability tighten. Bias and fairness require proactive detection and remediation strategies, including diverse data curation, auditing protocols, and impact assessments. Energy consumption and environmental footprint of large models are under scrutiny, prompting research into efficient architectures, model compression, and better training paradigms. Finally, workforce transformation—retraining, upskilling, and aligning incentives—will shape how organizations adopt ML at scale, ensuring that human judgment remains central to decision-making and governance.
FAQ
What is the difference between AI, machine learning, and deep learning?
Artificial intelligence is the broad umbrella that encompasses any system designed to emulate intelligent behavior. Machine learning is a subset of AI focused on algorithms that learn from data to make predictions or decisions, rather than relying on explicitly programmed rules. Deep learning is a subfield of machine learning that uses deep neural networks with multiple layers to extract hierarchical representations from data, often achieving high performance on perceptual tasks such as image and speech processing.
How do you measure ML model performance?
Model performance is measured using task-specific metrics that reflect how well the model meets business objectives. Common metrics include accuracy, precision, recall, F1 score for classification; mean absolute error, root mean squared error for regression; area under the ROC curve for rank-sensitive tasks; and calibration metrics to assess probabilistic outputs. Beyond pure accuracy, practitioners evaluate calibration, fairness, robustness to distribution shifts, latency, and the stability of results over time, all of which influence deployment decisions.
What is overfitting and underfitting, and how can they be prevented?
Overfitting occurs when a model captures noise or idiosyncrasies in the training data, leading to poor generalization to new data. Underfitting happens when a model is too simple to capture underlying patterns, resulting in poor performance on both training and unseen data. Prevention strategies include using more data, applying regularization (such as L1/L2 penalties), selecting appropriate model complexity, employing cross-validation, and performing feature engineering to provide more informative inputs. Monitoring validation performance during training helps detect and mitigate these issues early.